GeoGuessr Image Geolocation Model
Predicting latitude & longitude from a single image using deep learning. Built with ResNet-based classifiers, stratified sampling, and continent-level regressors.
Project Overview
Related Fields
Deep Learning, Computer Vision, Geospatial ML, Transfer Learning
Methods
ResNet/ViT modeling, Haversine loss, stratified sampling, sub-regressors
Dataset
OSV-5M (4.89M street-view images across 220+ countries)
Motivation
Humans use subtle cues to guess geographic location: vegetation, soil color, road markings, architecture, sun direction, and even license-plate shape.
Our goal: Can a model do the same from a single image?
- Predict latitude & longitude directly (regression)
- Leverage continent-level priors
- Handle extreme geographic imbalance in OSV-5M
Dataset & Data Cleaning
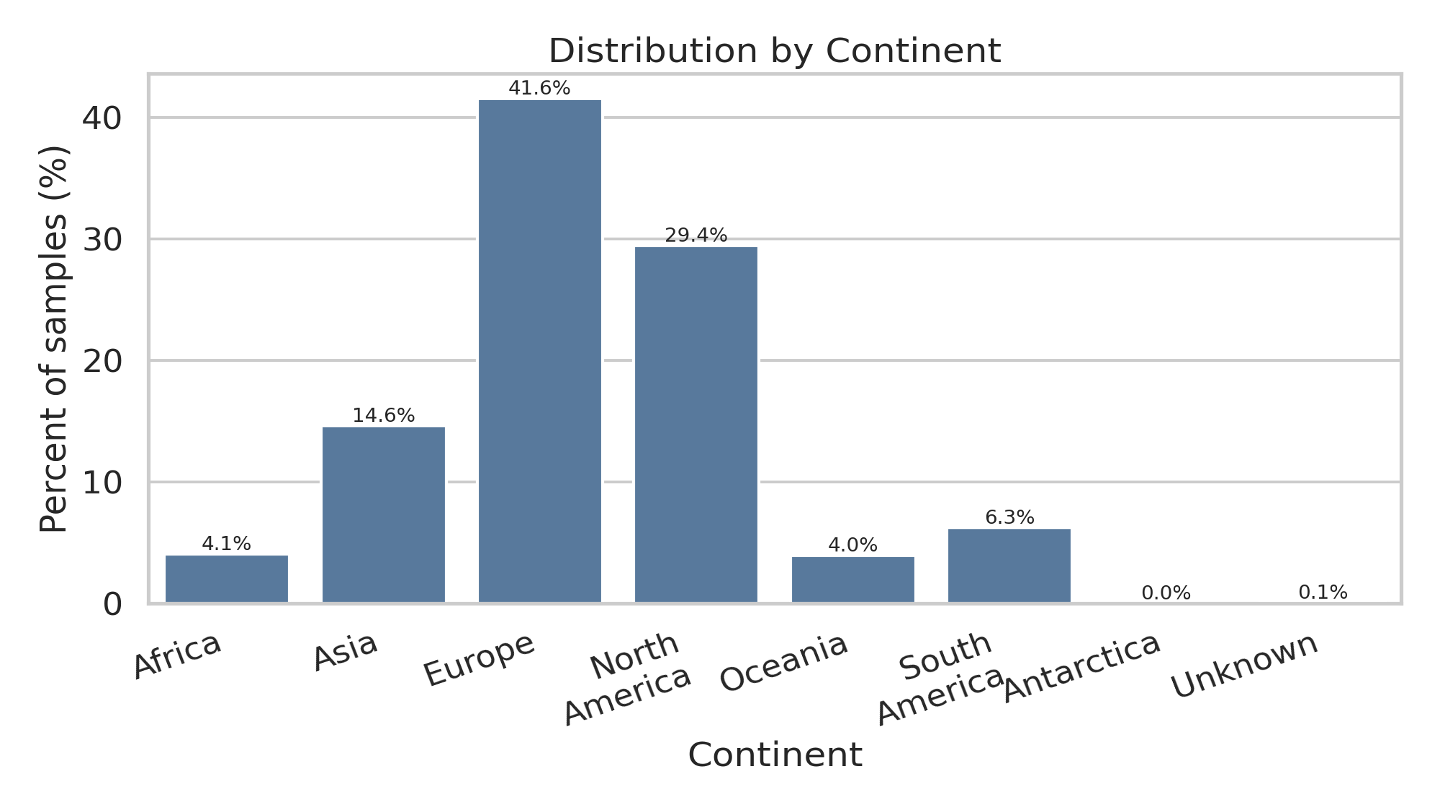
OSV-5M provides nearly five million raw street-view images, but its extreme size makes training difficult. A single 25-epoch run would take multiple days.
To make training feasible, we created a:
- 150,000-image stratified subset preserving the geographic distribution of the full dataset
- Training time reduced from 2+ days → 2.5 hours
- Balanced across 6 continents and 220+ countries
- Increase the size of subsets and test on the increasing subsets step by step
Baseline: Bias Regressor
We started with a simple baseline: predict the same (lat, lon) for every image (the dataset mean).
- Latitude mean: 32.94°
- Longitude mean: -11.29°
- Average Haversine distance: 6195.97 km
This baseline lets us evaluate whether any new approach beats a naïve global prior.
Approach 1 - Global ResNet Regressor
 5-layer regressor on the extracted features from ResNet18
5-layer regressor on the extracted features from ResNet18 First approach model architecture
First approach model architectureWe used a pretrained ResNet-18 backbone and added a 5-layer regressor head to predict (latitude, longitude) directly.
However, we learned:
- 1. The world is too large for a single regressor
- 2. Europe and Oceania look visually similar
- 3. South America and South Asia frequently get confused
- 4. Model often predicts locations in the ocean
Approach 2 - Country Classifier (ViT & ResNet50)
We experimented with a full country classifier.
Why not Vision Transformers?
- Though ViT performs best with very large, clean datasets, but our time and source constraints limited us
- OSV-5M is noisy and globally imbalanced
- Training ViT was slow and accuracy resembled random guessing
Why ResNet50?
- Stronger for natural imagery
- More efficient to fine-tune
- Better generalization on the subset
Why we didn't use ResNet50 and Country Classifier?
- We got really high training accuracy (98%), but validation accuracy was only 59.83%, which indicates overfitting
- OSV-5M has a large number of images concentrated on a few countries
- Country classifier is more complex and requires more fine-tuning
Final Approach - Continent Classifier + Sub-Regressors
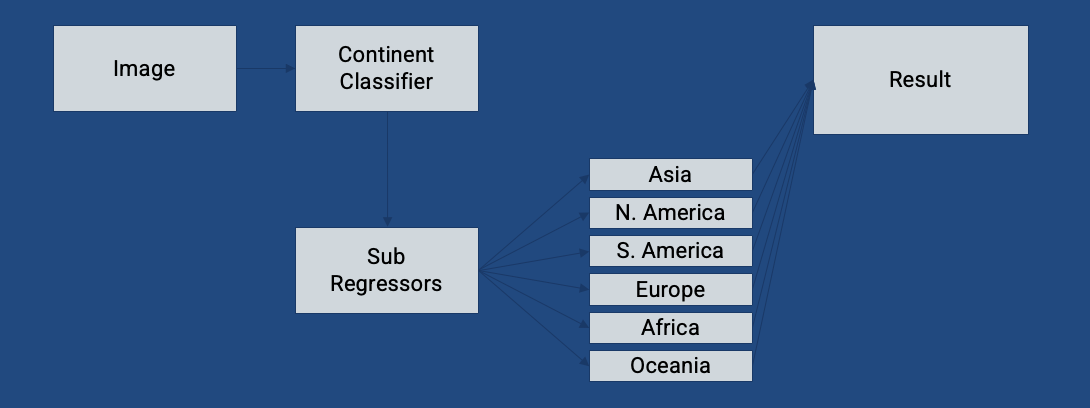
Our final architecture splits the world into logical regions:
- Stage 1 — Continent Classifier (RouterNet)
- Stage 2 — 6 continent-specific regressors
Each regressor fine-tunes the ResNet-18 backbone on its own regional dataset. This drastically improves accuracy, especially in well-represented regions such as:
- North America
- Central Europe
- Middle East
Final Output
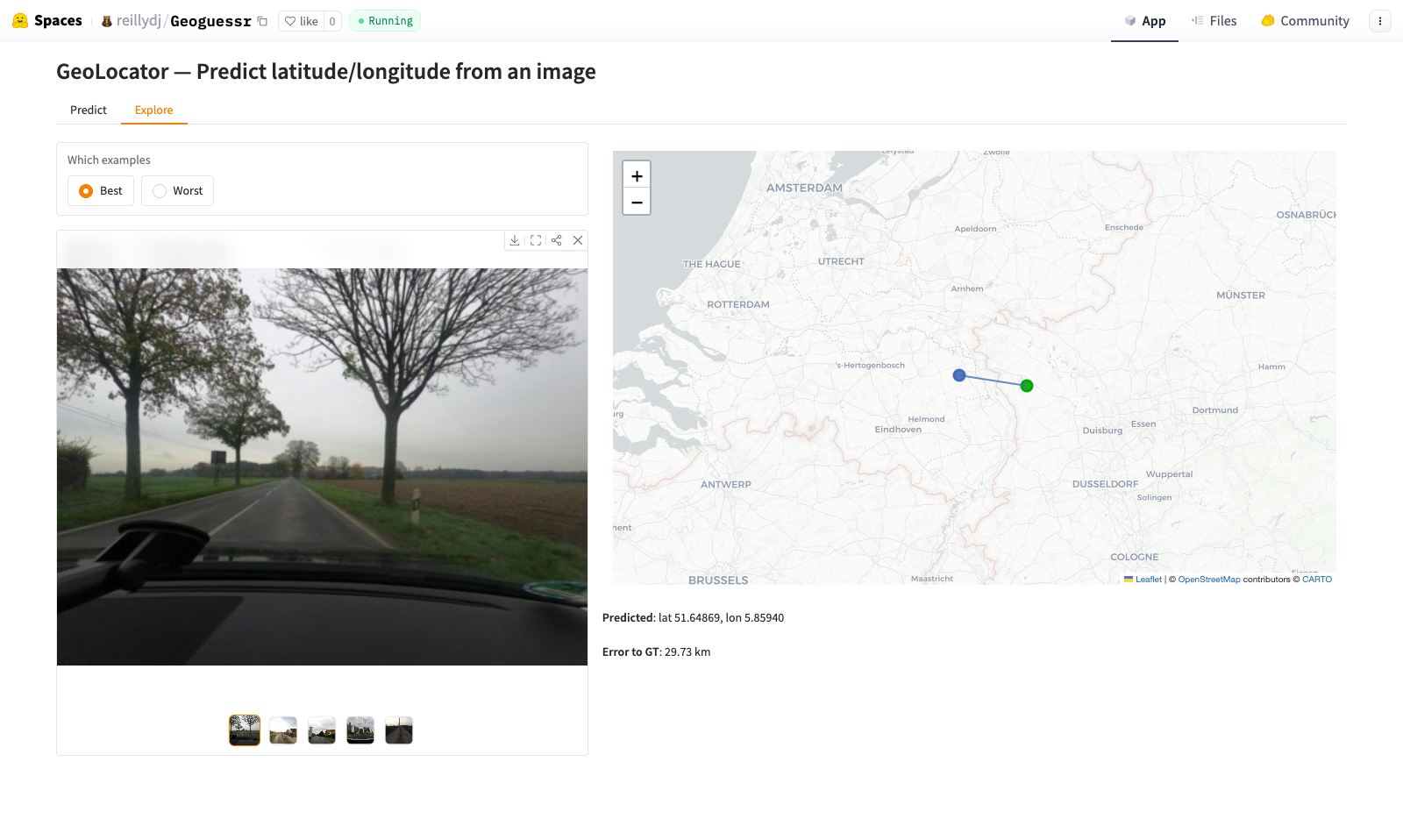
We deployed the model on HuggingFace Spaces for interactive testing. The model shows strong performance when visual cues align with dataset density. You can try our model here: GeoLocator - Predict latitude/longitude from an image
Strengths
- Predicts with very little context
- Succeeds in regions with strong visual identity (e.g., Middle East)
- Good at densely represented areas of the dataset
Weaknesses
- Cannot understand languages, signs, or landmarks
- Confuses regions with similar vegetation or architecture
- Still predicts ocean locations occasionally
Lessons Learned
- Big datasets require strategy (sampling, subsets, caching)
- Model choice matters — ViT is not always the answer
- Decompose complex problems (classification → regression)
- Geolocation requires both coarse and fine reasoning
Related Work
- PIGEON (Haas et al., 2024) — Geolocation using semantic geocells.
- GeoLocSFT (Yi & Shan, 2025) — Fine-tuning multimodal models for geolocation.
- IMAGEO-Bench (Li et al., 2024) — Benchmarking LLMs for spatial reasoning.